
大家好,今天要跟大家介紹我的瀏覽器會圖片辨識,一個瀏覽器套件(Chrome Extension)與圖片辨識(OCR API)結合的故事。OCR 是 Optical Character Recognition 的簡稱,簡單說就是圖片辨識的技術,主要目標是可以辨識圖片上的文字,我們的目標是瀏覽器會圖片辨識,讓我們可以將當前畫面上的文字複製出來,這邊的想像是,瀏覽器打開圖片後點選瀏覽器套件,接著圖片上的文字出現在我們的套件上,就可以將文字複製到別的地方了,所以做一個 Chrome Extension 串接圖片辨識 OCR API 就可以達成!
這邊共有兩個重點,一個是 Chrome Extension 的製作,另一個是串接 OCR API 的過程。
接下來我們直接開始動手做 -
實作 Chrome Extension 串接 OCR API
Step 1
根據 Google 官網,首先我們需要一個叫做 manifest.json 的檔案,新增一個資料夾並在該資料夾下新增 manifest.json 檔案內容如下:
{
"manifest_version": 2,
"name": "我的瀏覽器會圖片辨識",
"description": "我的瀏覽器會圖片辨識",
"version": "1.0.0",
"icons": {
"16": "icon.png",
"48": "icon.png",
"128": "icon.png"
},
"browser_action": {
"default_icon": "icon.png",
"default_popup": "popup.html"
},
"permissions": [
"tabs"
]
}
這邊定義你的 Chrome Extension 的名稱、描述、版本、圖片、會用到的權限等等,並將圖片 icon.png 放到相同的資料夾底下,這邊試做我三種大小用同一張圖片,大家可以再針對不同大小選用適當的圖片唷。
Step 2
開始製作要做的內容,首先先新增一個 popup.html 到你的資料夾下,檔案內容如下:
<!DOCTYPE html>
<html>
<head>
<title>我的瀏覽器會圖片辨識</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style type="text/css">
body {
margin: 10px;
min-width: 400px;
}
h1 {
font-size: 15px;
}
#popup {
display: flex;
align-items: center;
justify-content: space-between;
}
</style>
<script src="popup.js"></script>
</head>
<body>
<h1>我的瀏覽器會圖片辨識</h1>
<div id="popup">
<span>選擇圖片上要轉換成文字的語言</span>
<select id="select">
<option selected disabled hidden value=''>請選擇</option>
<option value="eng">英文</option>
<option value="cht">中文</option>
</select>
</div>
<hr>
<div id="result"></div>
</body>
</html>
這裡是點選你的 Chrome Extension 後會跳出來的畫面,我們先做兩種語言可以點選的按鈕。
Step 3
開始串接 OCR API,在寫程式碼前我們會需要能夠串接 API 的 Key,故前往 Free OCR API 點選 Register for free API Key,註冊並帳號認證成功後會收到 OCR.SPACE Free OCR API: Your free OCR API key 的 email,我們的 API Key 就在 mail 內,接著我們在相同資料夾下新增 popup.js,檔案內容如下:
document.addEventListener('DOMContentLoaded', () => {
const select = document.querySelector('#select');
const result = document.querySelector('#result');
// 當使用者選取語言時
select.addEventListener('change', (event) => {
const language = select.value;
// 抓取當前網址
chrome.tabs.getSelected((tab) => {
const tablink = tab.url;
// 準備需要傳遞給 OCR API 的參數
const formData = new FormData();
formData.append('url', tablink);
formData.append('language', language);
formData.append('apikey', 'your-api-key');
const url = 'https://api.ocr.space/parse/image';
// 對 OCR API 發送請求
fetch(url, {
method: 'POST',
body: formData
// 用 json() 解讀回傳的資訊
}).then(response => response.json())
.then((jsonData) => {
// 存取我們需要的資訊
const parsedResults = jsonData['ParsedResults'];
const errorMessage = jsonData['ErrorMessage'];
// 如果回傳的結果不是空的
if (parsedResults != null) {
// 獲得每一個結果的詳細內容
parsedResults.forEach((value) => {
let exitCode = value['FileParseExitCode'];
let parsedText = value['ParsedText'];
let errorMessage = value['ErrorMessage'];
// 如果分析回來的文字是空的,用 -1 表示
if (parsedText === '') {
exitCode = -1;
}
// 分析回來的情況 1 表示成功,其他情況顯示錯誤訊息
switch (+exitCode) {
case -1:
result.innerHTML = 'Error: parsed text is blank';
break;
case 1:
result.innerHTML += parsedText;
break;
default:
result.innerHTML = 'Error: ' + errorMessage;
break;
}
});
// 其他錯誤情況
} else {
result.innerHTML = 'Error: ' + errorMessage;
}
// 如果打 API 有錯誤,則將錯誤印在 console 上
}).catch((err) => {
console.log('Error:', err);
})
});
});
});
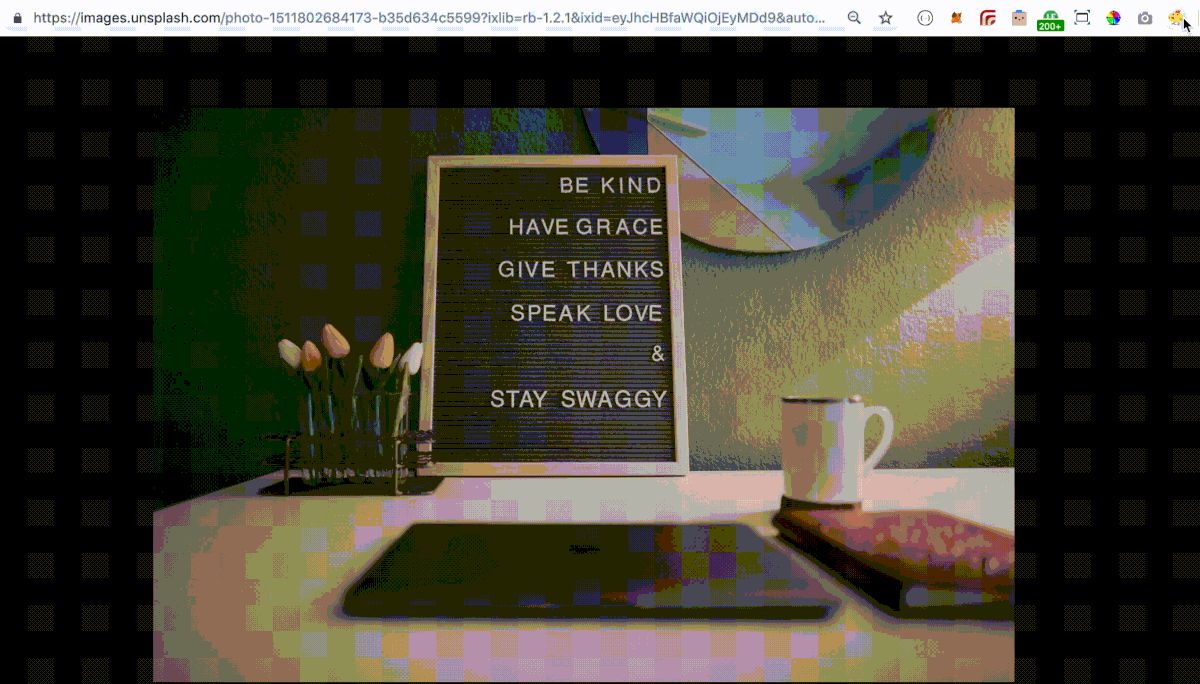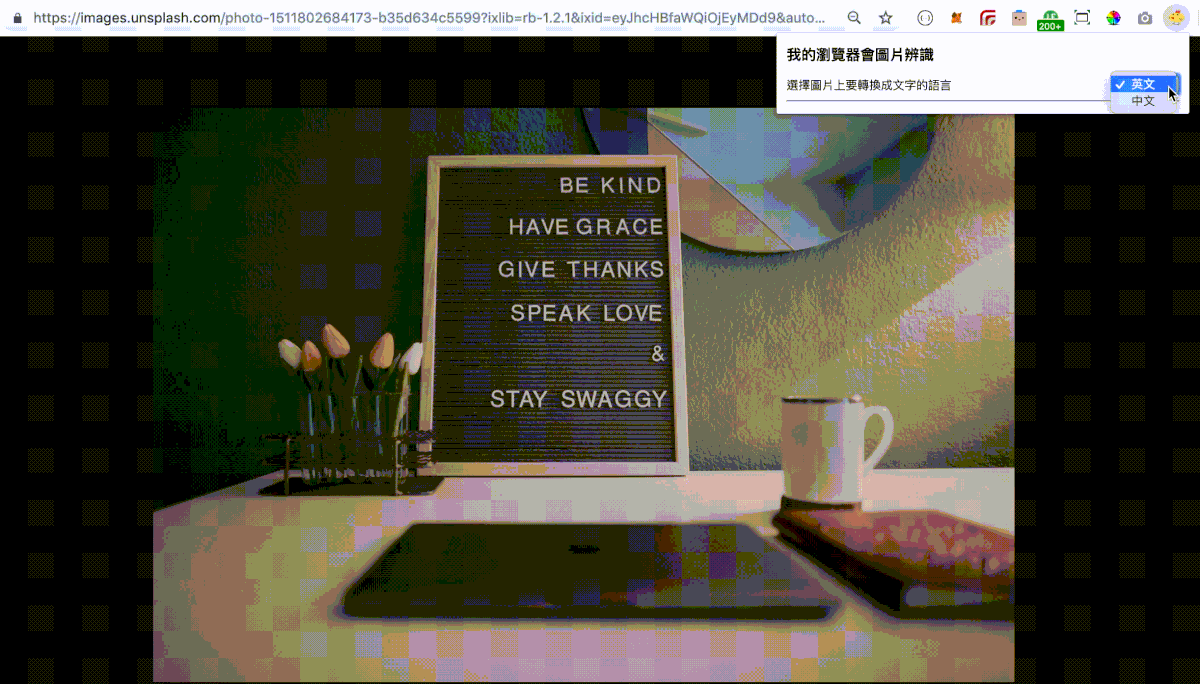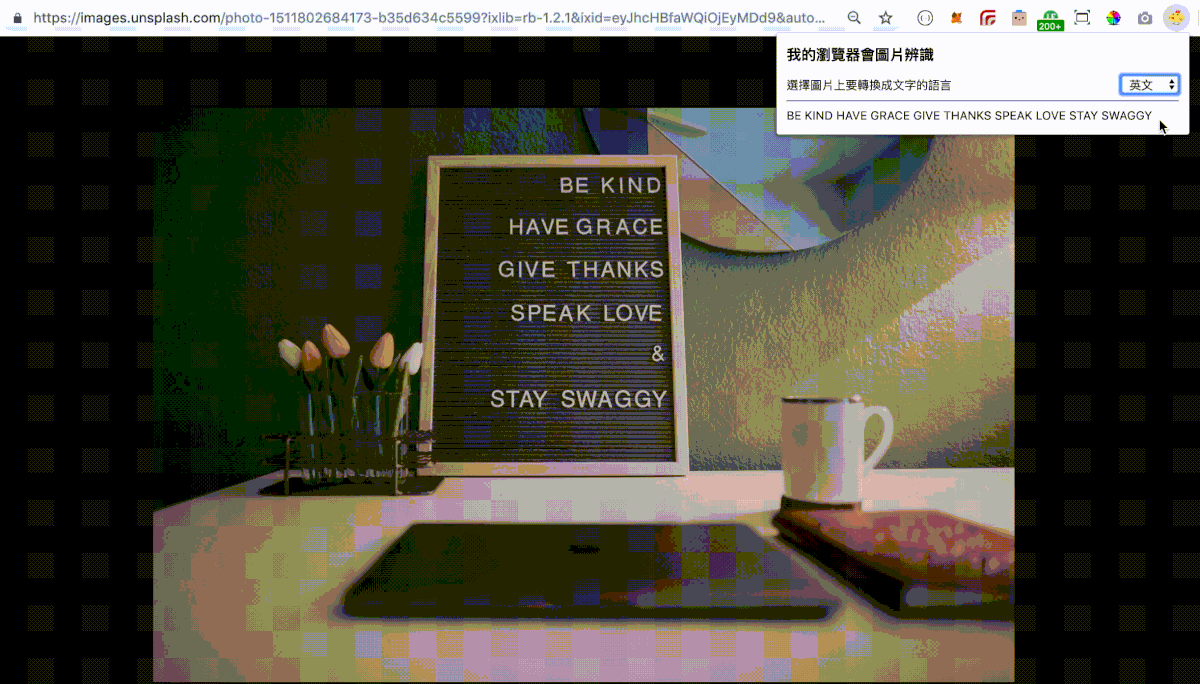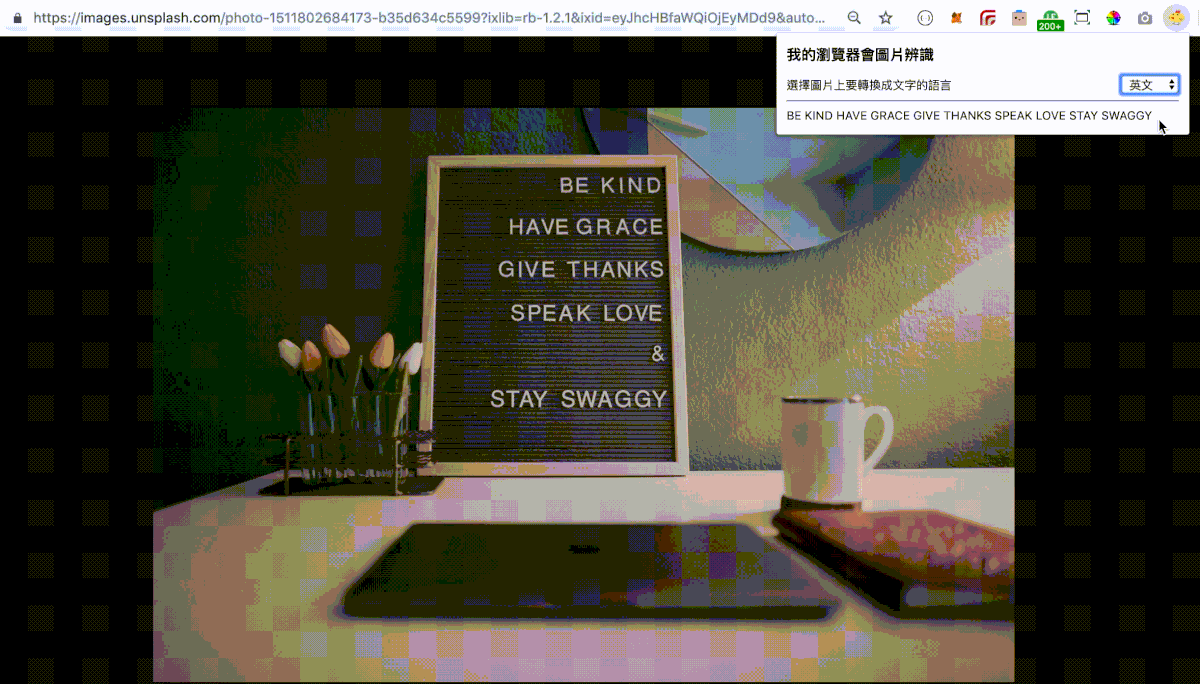
其中 your-api-key 請輸入在 Free OCR API 註冊得到的 API Key,這份檔案就是我們打 API 的主要內容,當使用者選取一種語言時,我們將需要的參數(formData),含當前的網址、選取的語言、API Key 打去 Free OCR API 並將收到的結果放在畫面上,這邊只示範瀏覽器網址是圖片的情況,其中 exitCode 可以在 Free OCR API 看到有幾種定義,這邊先只考慮傳進來是 1 成功的情況,並自訂 -1 有成功傳進來但是傳進來是空值的情況,其他不成功的情況直接抓錯誤訊息顯示, console.log('Error:', err) 方便開發時查看錯誤。
Step 4
最後我們的資料夾結構會是這樣:
chrome-extension-with-ocr-api
├── icon.png
├── manifest.json
├── popup.html
└── popup.js
接下來我們要把它放到自己的瀏覽器上,到 Chrome Extension 將右上角開發人員模式打開,重新整理後點選左上角 載入未封裝項目,選取剛剛完成的資料夾,接著看到你的 icon.png 出現在瀏覽器網址的旁邊就大功告成囉!現在可以用看看自己的 Chrome Extension 了!可以在 Google 搜尋一張網路上的圖片,點選在新分頁中開啟圖片,接著點選網址旁邊 icon.png 的小圖示,就可以開始用看看了。
最後結果如下:
總結
- 除了文章中示範的 Free OCR API 以外還有其他像是 Google Cloud Vision API、Microsoft Azure Computer Vision API 也都有提供 OCR 的技術,這邊大家也都可以練習看看唷,希望這篇文章可以激發大家的想法,發揮創意做出屬於自己的瀏覽器套件!
- 目前線上有一個叫做 Copyfish 的瀏覽器套件就是用 OCR API 做的,可以參考看看。
- 最後的程式碼放到 GitHub,提供大家參考。
- 另外想用 Ruby 玩玩看串接 Free OCR API 也可以參考 ocr_space。
👩🏫 課務小幫手:
✨ 想掌握 JavaScript 觀念和原理嗎?
我們有開設 📒 JavaScript / jQuery 前端開發入門實戰 課程唷 ❤️️
